隨著人工智能應用的爆發式增長,AI芯片作為算力的核心載體,其發展路徑與挑戰日益成為業界焦點。當前,AI芯片正面臨兩類關鍵瓶頸,同時呈現出三大發展趨勢,而存儲技術的創新則有望開拓性能提升的新疆界。
兩類瓶頸:算力與能效的挑戰
- 算力墻與內存墻:
- 算力墻:隨著模型參數量的指數級增長(如千億、萬億參數模型),對芯片峰值算力(TOPS)的需求已逼近物理極限。傳統架構下,單純堆砌計算單元帶來的收益遞減,且芯片面積、功耗和成本急劇上升。
- 內存墻:數據在存儲單元與計算單元之間的搬運成為主要性能瓶頸。頻繁的數據移動導致高延遲與高能耗,尤其在處理大規模矩陣運算時,內存帶寬不足嚴重制約了算力的有效利用,形成“存儲制約計算”的困境。
- 能效墻與通用性困境:
- 能效墻:AI訓練與推理的能耗日益驚人。在追求更高性能的如何降低每瓦特算力的能耗(即提升能效比)是芯片設計的關鍵挑戰,直接影響部署成本與可行性(如邊緣設備、數據中心)。
- 通用性與靈活性的平衡:專用芯片(ASIC)針對特定算法(如Transformer)效率極高,但難以適應快速演化的AI模型;通用芯片(如GPU)靈活性好,但往往在能效上做出妥協。如何實現動態可重構、軟硬件協同的架構成為難點。
三大趨勢:架構創新與生態演進
- 架構多元化與異構計算:
- 從傳統的CPU、GPU主導,走向CPU+GPU+XPU的異構融合。專用領域架構(DSA)針對AI負載優化,如TPU、NPU等;神經擬態芯片、光計算芯片等非馮·諾依曼架構也在探索中,旨在模擬人腦的高效計算模式。
- Chiplet(芯粒)與先進封裝:通過將大芯片拆分為多個小芯粒,采用2.5D/3D封裝集成,提升良率、降低設計成本,并實現內存與計算單元的近距離互連,緩解內存墻問題。
- 軟件定義硬件與編譯優化:
- 硬件不再孤立發展,而是與編譯器、框架深度耦合。AI編譯技術(如MLIR、TVM)通過對計算圖進行優化、調度與代碼生成,使同一硬件能高效支持多樣化的模型,提升通用性。
- 開源指令集(如RISC-V)與開放芯片生態正在降低設計門檻,推動定制化AI芯片的繁榮。
- 場景化與全棧優化:
- 芯片設計日益貼近終端場景:云端訓練芯片追求極致算力與精度;邊緣推理芯片注重低功耗、實時性;終端設備則強調整合度與成本。
- “存儲-計算-通信”協同設計:從單一算力指標轉向全棧優化,包括內存層次設計、片間互聯技術(如NVLink、CXL)及集群網絡,以提升系統整體效率。
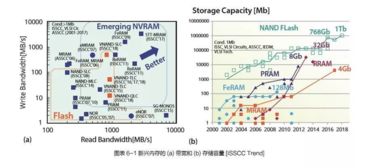
存儲技術:開拓性能新疆界的關鍵
存儲技術的創新正成為打破AI芯片瓶頸的核心突破口:
- 存算一體(Computing-in-Memory):
- 將計算單元嵌入存儲陣列中,直接在數據存儲位置進行處理,極大減少數據搬運。基于SRAM、DRAM或新興非易失存儲器(如ReRAM、PCM)的存算一體芯片,已在邊緣推理場景展示出數量級的能效提升潛力。
- 高帶寬內存(HBM)與先進封裝:
- HBM通過硅通孔(TSV)技術將DRAM堆疊在邏輯芯片上,提供遠超GDDR的帶寬(如HBM3帶寬可達819GB/s以上)。結合CoWoS等2.5D/3D封裝,實現了“內存緊貼計算”,有效緩解帶寬瓶頸。
- 新型非易失存儲器與近存計算:
- ReRAM(阻變存儲器)、MRAM(磁阻存儲器)等兼具高速、低功耗、高密度特性,不僅可用于存算一體,也可構建高速緩存或持久內存層,優化數據存取路徑。
- 近存計算將計算單元置于內存芯片附近,作為存算一體的過渡方案,已在部分AI加速器中應用。
- 存儲層級智能化:
- 通過硬件與系統軟件協同,動態管理數據在各級存儲(如HBM、DDR、NVMe SSD)間的分布,預測數據訪問模式,實現數據預取與緩存優化,最大化內存帶寬利用率。
###
AI芯片的競賽已從單純算力比拼,進入架構創新、能效決勝、軟硬協同的深水區。兩類瓶頸(算力/內存墻、能效/通用性)倒逼技術變革,三大趨勢(異構融合、軟件定義、場景化)指引發展方向。而存儲技術的突破——尤其是存算一體與先進封裝——正為AI芯片開拓出新的性能疆界,有望在未來幾年內催生出更高效、更靈活的算力基石,賦能千行百業的智能化升級。技術開發者需密切關注這些交叉領域的進展,在算法、硬件與系統的協同優化中尋找創新機會。